Storage Replica is a new feature in Windows Server 2016 that enables to replicate data from the storage level when you are using Windows Storage solution. Storage Replica uses SMB3 to replicate and can leverage on RDMA to increase throughput and to decrease CPU utilization.
Storage Replica implementation
Currently Storage Replica supports four different scenarios:
- Stretch cluster implemented by using Storage Replica
- Cluster-To-Cluster storage replication
- Server-To-Server storage replication
- Server-To-Self replication (to replicate between volumes in a single machine)

In the above scenario, a cluster is stretched between two rooms. The machines in the Room 1 have a first storage solution while the servers in Room 2 have another storage solution. To synchronize data between storage solutions, the Storage Replica can be used. In this way, the cluster can be stretched because the stored data are the same. Even if Storage Replica enables to make Stretched cluster easier, I still don’t like this kind of solution especially for Hyper-V cluster. This kind of solution bring complexity when we simplify infrastructure as Hyper-Convergence allows.

The above solution is a Cluster-To-Cluster replication. Let’s think about two rooms (in two different locations) with one cluster in each. The first cluster is the active one while the other is the passive. The storage is replicated from the active to the passive cluster. Now the first cluster brings down. The passive cluster can start applications because all the data have been replicated. This solution brings a good DRP solution.

The above solution works as same as Cluster-To-Cluster replication except that instead of a cluster we have just a single server. We have two servers in two different locations. So the first server is the active one while the server 2 is the passive. Even if the server 1 is down, the server 2 can start applications. Thanks to Storage Replica, we have implemented a DRP easily.
To finish, it is also possible to replicate volumes in a single server. Thanks to this, you can replace your Robocopy processJ.
Replication mode
Storage Replica requires at least two volumes to work: the logs and the data volume. The data volume contains the data that you want replicated. The logs volume should be high speed (as SATA SSD or NVMe SSD) and it’s used for log replication.
Storage Replica supports two different replication modes:
- Synchronous
- Asynchronous (Server-To-Server only)
The synchronous replication is a near real-time replication, which offers a Zero Data Loss. This solution should be chosen for HA and DR solution. However, be careful because there is a risk of degraded application performance because the application write is acknowledged once the replication has been done. This is why the Logs volume should be on SSD devices.

- Application writes data
- Log data is written and the data is replicated to the remote site
- Log data is written at the remote site
- Acknowledgement from the remote site
- Application write acknowledged
t & t1 : Data flushed to the volume, logs always write through
The Asynchronous replication brings less risk of degraded application performance because the application write is acknowledged once the log data is written. However, because the replication is not near real-time replication, there is a risk of a loss of data (Near Zero Data Loss). So the latency and the distance are less important than if synchronous replication was implemented.

- Application writes data
- Log data written
- Application write acknowledged
- Data replicated to the remote site
- Log data written at the remote site
- Acknowledgement from the remote site
t & t1 : Data flushed to the volume, logs always write through
Implementation Example
In this implementation example, I will replicate data from a first cluster to a second cluster (Cluster-To-Cluster). The storage solution of each cluster is based on Storage Spaces Direct.
My both Clusters are implemented on Nano Server nodes. If I follow the documentation I need these packages:
- File Server role and other storage components
- Reverse forwarders
- Deploy Nano Server image with EnableRemoteManagementPort option
For more information about Nano Server, you can read this topic.
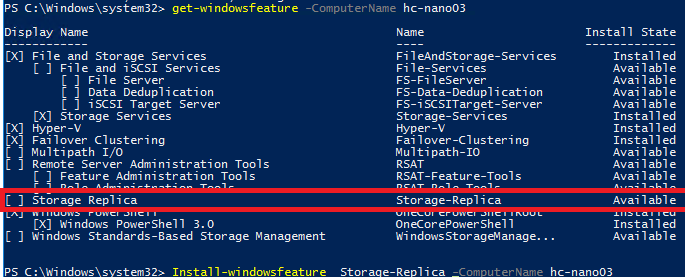
Once your node deployed, you need to install the Storage Replica feature. For that you can run the below command:
Install-WindowsFeature Storage-Replica –ComputerName <ComputerName>
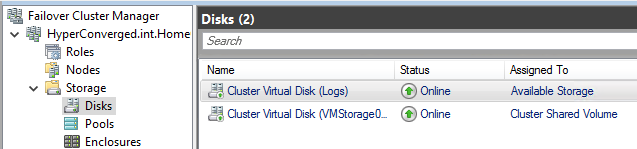
Regarding my clusters, I have two disks: the VMStorage01 and a Logs volume. I have attributed the L letter to the Logs volume. It is important that the volume are identical between source and destination cluster. Otherwise, it won’t work.

From the cluster view, it seems like that:
My both clusters are configured the same. Then I run the below command to grand Storage Replica access from the first cluster to the second and vice versa.
Grant-SRAccess -ComputerName <a Node of the first cluster> -Cluster <second cluster name> Grant-SRAccess -ComputerName <a Node of the second cluster> -Cluster <first cluster name>
To finish, I run the New-SRPartnership command as below:
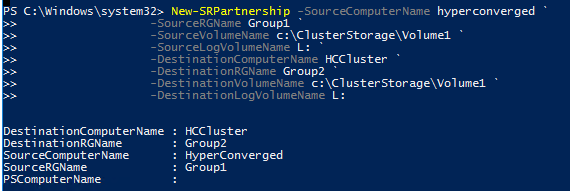
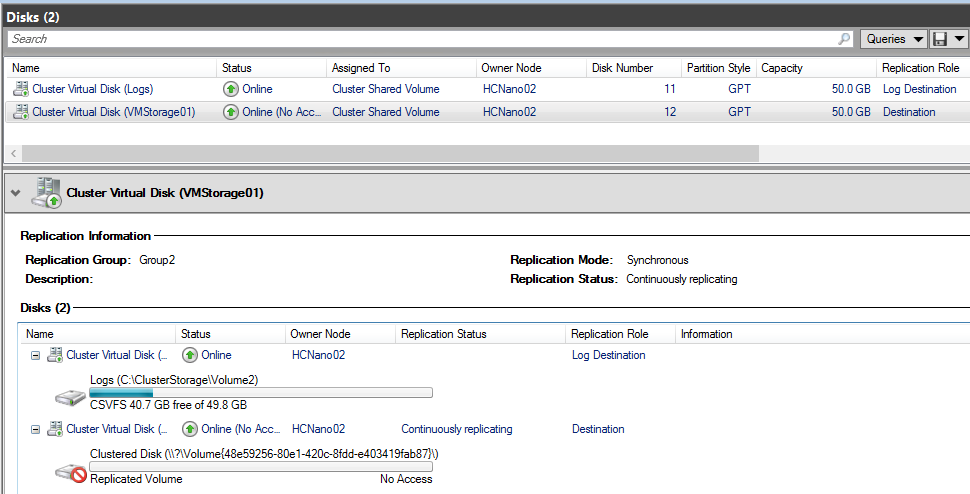
And below the result in the disk view of the first cluster. The logs disk has the log source replication role and the VMStorage01 has the Source replication role.
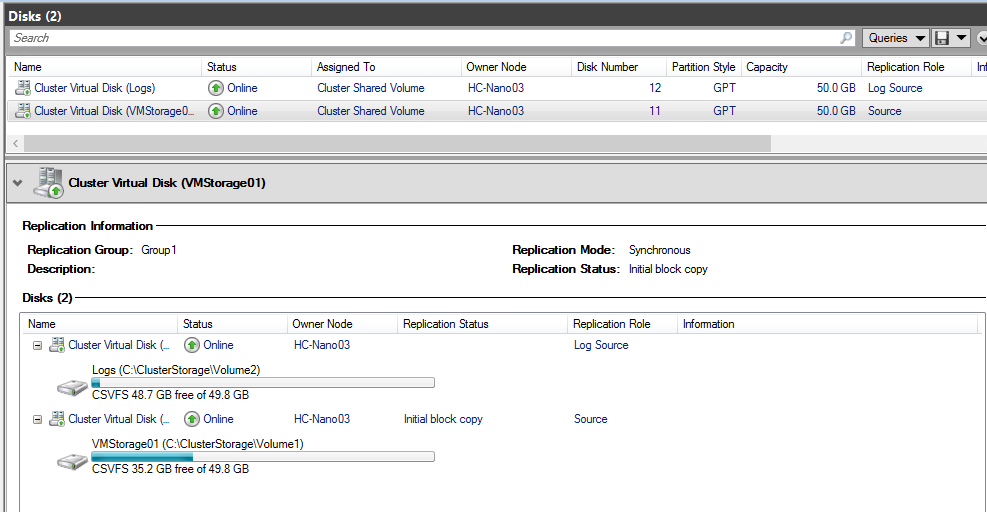
On the destination side, the destination volume is no more accessible. Once the initial replication is finished, the replication status is continuously replicating. The Logs disk becomes the log destination replication role and the VMStorage01 disk becomes the destination replication role.